|
|
С. С. Юдицкий |
 |
Прикладные программы в вашей сети работают медленно, компьютеры «зависают». Программисты говорят, что в этом виновата сеть, а ее администратор — что прикладные программы. Нужно разобраться, кто из них прав, кто виноват и что делать?
Прежде всего нужно решить, что понимать под термином «сеть» и что под понятием «диагностика сети». Итак, сеть — это аппаратно-программный комплекс, состоящий из сетевой ОС, пассивного и активного сетевого оборудования. СУБД же следует считать частью прикладной программы, а не сети. Таким образом, если на сервере из-за дефектов СУБД портится индексный файл, то проблема заключается в прикладной программе, а не в сети. А диагностикой сети считается процесс, при котором определяются причины, приводящие к замедлению или неустойчивости работы в ней прикладных программ. Иногда под диагностикой сети подразумевается только тестирование ее кабельной системы на соответствие принятым стандартам, например TIA TSB-67, однако такая трактовка все-таки слишком узка.
Несомненно, кабельная система — важная составляющая локальной сети, но далеко не единственная и не самая сложная с точки зрения диагностики. С помощью специального прибора, обычно называемого кабельным сканером или кабельным тестером, выявляются дефекты кабельной системы сети. Однако на скорость и надежность работы прикладных программ в сети большое влияние оказывают качество, исправность и производительность активного сетевого оборудования (плат, коммутаторов, концентраторов), соответствие архитектуры сети решаемым задачам, параметры настройки сетевой ОС, надежность и производительность ПК рабочих станций и серверов и, наконец, качество прикладных программ.
Диагностика любой сложной системы, будь то компьютерная сеть, двигатель или сердечно-сосудистая система человека, включает три этапа:
- |
во-первых, нужно выяснить, как диагностируемая система должна работать;
|
- |
во-вторых, следует достоверно определить, как диагностируемая система реально работает;
|
-
| в-третьих, если диагностируемая система в действительности функционирует не так, как должна, то необходимо правильно установить, почему это происходит.
|
Как должна работать сеть или как оценить ее качество? Ответ на этот вопрос вовсе не столь однозначен, как может показаться сначала. Если задать подобный вопрос администраторам сети, то, скорее всего, они дадут один из приведенных ниже ответов.
Первый вариант такой: «Если пользователи не жалуются, значит, сеть работает хорошо». На первый взгляд подобный ответ можно было бы считать правильным. Однако недовольство пользователей все-таки субъективный критерий — одни их них недовольны, когда прикладная программа отрабатывает запрос дольше 5 с, а других вполне удовлетворит даже то, что запрос вообще выполняется, причем неважно, как быстро, лишь бы программа не зависала. Как писал М. Жванецкий, наша обувь тоже хорошая, если другой никогда не носили. Следовательно, у администратора сети нет средств и методик, которые позволяют объективно, в цифрах, оценить качество работы сети.
Второй вариант ответа: «Базовые параметры, характеризующие работу сети, не должны превышать определенные пороговые значения». За такие базовые параметры приняты, в частности, утилизация канала связи сети, общее число ошибок передачи данных, доля широковещательных и групповых пакетов. Это, конечно, правильно, однако в данном случае администратор скорее говорит о том, как сеть не должна работать, а не как должна. Ведь понятно, что отсутствие плохих новостей не всегда можно считать хорошей новостью.
Третий вариант такой: «Работу сети можно назвать хорошей тогда, когда она обеспечивает требуемое время реакции для прикладных программ, например не более 3 с». Поскольку время реакции всегда относится к конкретной операции прикладных программ, администратор должен уточнить, к какой именно. Поэтому более правильной была бы следующая формулировка ответа: «Наша сеть должна функционировать так, чтобы любой пользователь программы Х при выполнении операции Y ждал не более n секунд».
Второй вариант соответствует традиционному подходу к оценке качества работы сети, когда за основные критерии приняты характеристики сетевого трафика. В данном случае применяются такие диагностические средства, как анализаторы сетевых протоколов, анализаторы сетевого трафика, сетевые мониторы и программы на основе SNMP и RMON (см. врезку «Традиционный подход к оценке качества сети»).
Третий вариант ответа соответствует такому подходу, при котором одним из основных критериев качества сети является время реакции прикладных программ, и потому его можно назвать подходом от прикладной задачи. Он был реализован в широком спектре продуктов под общим названием «ПО для управления производительностью приложений», или Application Performance Management Software. Основные игроки на этом секторе рынка — компании CompuWare, NetScout, BMC Software и др.
Рассмотрим сначала традиционный подход. К его основным достоинствам можно отнести простоту и удобство решения значительного количества наиболее распространенных, но относительно несложных сетевых проблем. Так, если в сети имеется какой-то неисправный компонент, приводящий к искажению передаваемых по сети пакетов, то подобный дефект можно довольно просто локализовать с помощью традиционного подхода. Чтобы обнаружить искаженный пакет и определить, кто его послал, нужно проанализировать все проходящие по сети пакеты. Кроме того, традиционный подход позволяет справляться и с другими часто встречающимися дефектами, в частности с перегруженностью сети и «широковещательным штормом». Можно также определить те станции, где неэффективно используется сеть, и те, которые наиболее сильно загружают ее. Все это можно «увидеть» при анализе сетевого трафика, а вызваны подобные проблемы, как правило, явными неисправностями кабельной системы, активного оборудования или архитектуры сети (наличие очевидных узких мест).
Теперь о двух основных недостатках традиционного подхода. Первый заключается в том, что трудно разобраться с такими сетевыми дефектами, которые нельзя увидеть при анализе трафика, например с неисправной платой или драйвером, которые теряют сетевые кадры. Очень часто в процессе разрешения конкретных задач можно столкнуться с ситуацией, когда явных дефектов не видно (нет ошибок, низкая утилизация сети, мало широковещательных пакетов и т.д.), а сеть или прикладные программы работают плохо. В этих случаях традиционный подход малоэффективен.
Второй недостаток более существен, чем первый. Он заключается в том, что традиционный подход не позволяет однозначно определить, во-первых, адекватно ли качество сети (в частности, ее пропускная способность) требованиям эксплуатирующихся там пользовательских программ, и, во-вторых, что надо сделать, чтобы программы работали быстрее.
Любая, даже самая маленькая сеть состоит как минимум из трех компонентов: рабочей станции, канала связи и сервера. На время реакции прикладной программы влияет производительность каждого из компонентов. Однако значимость параметра для каждой прикладной программы своя. Время реакции одних программ в большей степени зависит от производительности сервера (например, клиент-серверные приложения), других — от производительности канала связи, третьих — от производительности рабочих станций и т.д. Предположим, что время выполнения какой-либо операции распределяется между компонентами следующим образом: 75% времени — на сервер, 10% — на передачу данных по сети, 15% — на рабочую станцию. Таким образом, даже если сеть будет работать со скоростью света, то все равно операция более чем на 10% не ускорится.
Поэтому, чтобы улучшить работу конкретных прикладных программ в сети, следует выяснить, какие ее компоненты оказывают наибольшее влияние на время реакции этих программ, иначе и модернизация не поможет. Традиционный подход к оценке качества сети не дает однозначных ответов на подобные вопросы. Именно поэтому в последнее время все более распространенным становится подход «от прикладной задачи». Он отличается от традиционного тем, что здесь измеряются не только параметры, характеризующие функционирование сети, но и показатели, определяющие работу пользовательских программ.
Основным параметром, от которого зависит работа пользовательского приложения в сети, является его время реакции при выполнении сетевых операций (или транзакций). Оно отсчитывается от момента нажатия клавиши или левой кнопки мыши до появления на экране дисплея требуемой информации. Другими словами, это то время, которое требуется пользовательскому приложению для выполнения запроса пользователя с помощью сети.
Если реакция прикладных программ достаточно быстрая и они работают надежно, значит, сеть хорошая. (Обратного утверждения, как правило, сделать нельзя.) И при этом не так уж важно, какие характеристики имеет сетевой трафик, главное — сеть выполняет свои функции.
На вопрос, какое время реакции можно считать хорошим, есть однозначный ответ. Специальные исследования, проведенные американскими психологами, показали, что для прикладных программ при выполнении периодически повторяющихся операций оно не должно превышать 2—3 с. Если же это время оказывается большим, то пользователи быстрее устают и чаще ошибаются.
Разумеется, управлять можно только тем, что измеряется. Поэтому если требуется управлять временем реакции прикладных программ, то его надо суметь определить. А это как раз и делают программы для управления производительностью приложений, о которых уже упоминалось. (Например, Observer компании Network Instruments, LANalyzer for Windows компании Novell, NetMetrix компании Hewlett-Packard.)
Однако основная масса таких программ вряд ли в настоящее время может получить широкое распространение в России по трем причинам. Во-первых, их стоимость очень высока. Так, мне неизвестно ни одной западной программы подобного класса ценой существенно ниже 10 000 долл. Во-вторых, большинство из них ориентированы в первую очередь на приложения, работающие с базами данных типа Oracle, Sybase, Informix и т. п., доля которых на нашем рынке пока относительно невелика. В-третьих, в отечественных прикладных программах, как правило, не уделено должного внимания вопросам тестирования приложений с точки зрения эффективности их работы в различных сетевых архитектурах. И потому в случае, когда какая-либо прикладная программа работает медленно или со сбоями, трудно определить, чей это дефект — сети или самой прикладной программы. Для отечественных пользователей первичным является вопрос: кто виноват в медленной или неустойчивой работе прикладных программ — сеть или они сами? Только убедившись, что прикладное ПО не имеет явных дефектов и может работать быстрее, следует принимать решение об изменении архитектуры сети.
Например, время реакции приложения Х в сети составляет 15 с, а его нужно уменьшить до 3 с. Если приложение разработано на стороне, то неизвестно, обусловлено ли такое время реакции особенностями сети или просто приложение не может работать быстрее. Опыт свидетельствует, что этого обычно не знают даже создатели ПО. И потому перед измерением времени реакции приложений следует проверить, нет ли в сети дефектов, иначе говоря, надо предварительно отделить дефекты сети от дефектов приложений. И только убедившись, что в сети их не обнаружено, можно измерять время реакции прикладных программ и на основании этого оптимизировать архитектуру сети или модернизировать сетевое оборудование.
Чтобы произвести такое разделение дефектов, следует выполнить в сети специальное (тестовое) приложение с определенным временем реакции. Если при работе такого приложения именно оно и будет получено, то, значит, в сети нет дефектов. В противном случае необходимо выяснить причину того, почему время реакции тестового приложения получилось неадекватным, и ликвидировать дефект.
Вполне понятно, что таким тестовым приложением не может быть любая прикладная программа, поскольку оно должно измерять время выполнения своих операций. Обычная программа этого, естественно, не делает. Не подойдет и копирование файлов между рабочей станцией и сервером — полученные измерения будут неточными.
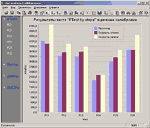
Одним из программных продуктов, который целесообразно использовать для оценки качества сети, является программный пакет FTest компании ProLAN (см. врезку «FTest: скорость как основной критерий качества сети»).
Он позволяет точно количественно оценить, как реально работает сеть. Это нужно и администраторам сетей, и системным интеграторам, и даже компаниям, внедряющим прикладные программы. Администратору сети такие оценки помогают отделить дефекты сети от дефектов прикладных программ, чтобы определить, кому предъявлять претензии: системному интегратору или компании-разработчику. Если же кто-то из последних не согласится с мнением администратора, то сможет аргументированно, с цифрами в руках, доказать свою правоту.
Для компании, внедряющей прикладные программы (иначе — компания-разработчик), количественные оценки качества работы сети просто жизненно необходимы. Чтобы застраховаться от тех случаев, когда прикладная программа внедряется заведомо в дефектной сети, нужно еще до внедрения ПО определить, исправлена ли сама сеть. Это легко сделать, имея количественные оценки качества работы сети.
Разработчик должен сообщить пользователям или заказчикам, какой должна быть сеть, чтобы внедряемые прикладные программы работали быстро. Например, даются рекомендации относительно архитектуры сети и конфигурации серверов, однако зачастую они бывают слишком общими, поскольку не сообщают количественных оценок того, как работают в таких сетях. Легко найти две сети Ethernet, удовлетворяющие подобным требованиям, но в одной из них можно работать со скоростью 50 Кбайт/с, а в другой — 500 Кбайт/с. Поэтому, давая советы конечным заказчикам, более правильно говорить не столько об архитектуре, сколько о скоростных характеристиках сети.
Для системного интегратора высокие количественные оценки качества построенной им сети — доказательство его профессионализма и хорошего качества выполненных работ. А вот выборочная передача файлов на сервер и обратно не является свидетельством хорошей работы сети. Она, как и после монтажа кабельной системы сети, проверяется специальным тестером. Это страхует системного интегратора от необоснованных претензий со стороны администратора или разработчика прикладных программ.
|
 |
Традиционный подход к оценке качества сети
Как реально работает сеть? В рамках традиционного подхода ответ на этот вопрос делается на основе анализа сетевого трафика, т. е. всех проходящих по сети пакетов. Естественно, чтобы информацию проанализировать, ее нужно получить. Сделать это можно двумя методами: пассивным прослушиванием канала связи либо опросом активного оборудования. Диагностические средства, использующие метод пассивного прослушивания, называются анализаторами сетевых протоколов. Опрос активного оборудования чаще всего осуществляется по протоколу SNMP, и потому диагностические средства, основанные на методе опроса, называются программами на базе SNMP.
Независимо от метода получения информации о сетевом трафике различные диагностические средства обычно проводят его анализ с разной степенью детализации (или глубины), включающей получение статистики по сетевому трафику, декодирование протоколов и экспертный анализ трассы. Статистика по сетевому трафику — первый уровень детализации. Она может быть текущей (интервал усреднения информации — от одной до нескольких секунд) или долговременной (интервал усреднения информации — от одной минуты до нескольких часов). Текущая статистика позволяет определить, как сеть работает в данный момент времени, а долговременная — установить так называемые тенденции (trends) в использовании сети.
Статистика по сетевому трафику, как правило, включает в себя несколько видов информации.
- |
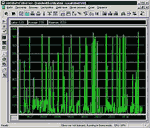
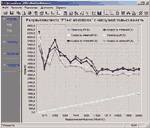
Утилизация канала связи, или процент его используемой пропускной способности. Считается, что текущая утилизация канала связи сети Ethernet не должна в течение длительного времени превышать 35%, а долговременная — 20%. На рис. 1 показан график текущей утилизации сети Ethernet, полученный анализатором протоколов Observer Light компании Network Instruments (USA).
|
- |
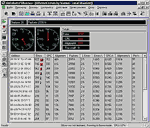
Общее число ошибок передачи данных и их распределение по станциям. Считается, что допустимое количество ошибок не должно превышать 0,01% от числа переданных пакетов. На рис. 2 представлено распределение ошибок передачи данных по станциям сети и по типам неисправностей, полученное анализатором протоколов Observer Light.
|
-
| Распределение станций по числу переданных в сеть пакетов (наиболее активные станции). Эта информация позволяет определить, соответствует ли архитектура сети тем требованиям, которые станции предъявляют к ней. А чем активней станция и чем критичней ее время реакции для пользователя, тем большую полосу пропускания сети она должна получить.
|
-
| Распределение пакетов по типам: индивидуальным, многоадресным или групповым и широковещательным. Обычно в исправной сети число широковещательных и групповых пакетов не должно превышать 8% от их общего числа.
|
-
| Распределение пакетов по протоколам и субпротоколам, позволяющее определить, есть ли в сети неиспользуемые протоколы и какие протоколы какие ресурсы сети потребляют.
|
-
| Распределение пакетов по длинам. Принято, что чем меньше в сети коротких кадров, тем эффективнее прикладные программы используют полосу пропускания сети. (Подробнее о статистической информации см. LAN № 7–8/98 «Искусство диагностики локальных сетей», LAN № 9/98 «Узкие места в локальных сетях».)
|
Второй уровень детализации в анализе трафика представлен функциями захвата пакетов и декодирования содержащихся в этих пакетах протоколов. Захват пакетов — это запись в буфер диагностического средства содержимого проходящих по сети пакетов. Поскольку по сети проходит много пакетов, но не все они представляют интерес для анализа, в диагностических средствах предусмотрены функции фильтрации. Входные фильтры позволяют захватывать в буфер только пакеты, удовлетворяющие определенным критериям, например пакеты от заданного узла или пакеты, содержащие конкретный протокол.
Декодирование протоколов позволяет выявить такие дефекты, которые невозможно найти, основываясь на анализе статистической информации. Чаще всего оно применяется тогда, когда необходимо определить причину отсутствия связи между узлами сети, например установить, из-за чего невозможно подключить конкретную станцию к заданному серверу. (Более подробно о декодировании протоколов программой Observer Light см. LAN № 1/99 «Анализ сетевых протоколов как метод оптимизации сети».)
Третий уровень детализации в анализе трафика представлен функциями экспертного анализа проходящих по сети пакетов (или трассы). Некоторые диагностические средства анализируют пакеты, предварительно захваченные в буфер, другие анализируют их на лету. Экспертный анализ очень полезен тогда, когда требуется выявить нежелательные события в работе протоколов транспортного и прикладного уровней, которые обычно свидетельствуют о наличии дефекта или узкого места в сети. Например, для протокола TCP такими событиями считаются повторные передачи (TCP retransmissions), появление пакетов с нулевым размером окна, большие задержки при передаче пакетов и др. Выявить такие события без функций экспертного анализа практически невозможно, так как для этого придется проанализировать сотни и тысячи сетевых пакетов.
|